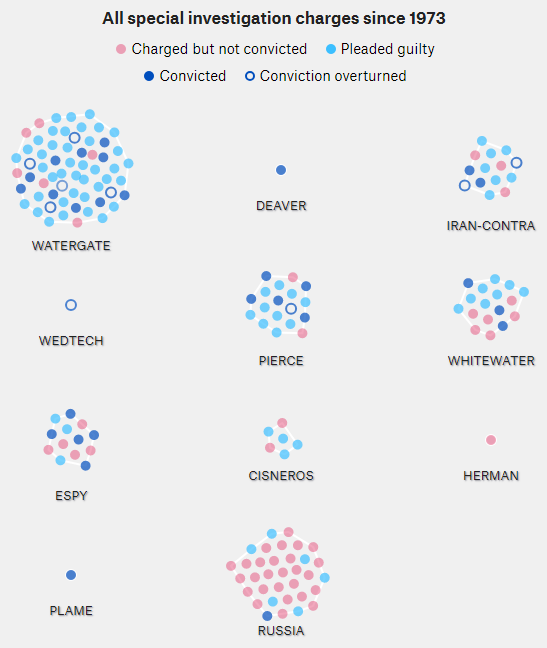
538، این تجسم جالب از تحقیقات روسیه را در زمینه واترگیت، وایتواتر و سایر تحقیقات تاریخی داشت.
تماشای نسخه اصلی سرگرمکننده است، اما درک پویایی زمان از انیمیشن برایم دشوار بود. آیا تحقیقات روسیه برای بلوغ خود (660 روز و شمارش) نسبت به واترگیت (مجموعاً 1492 روز) کیفرخواستهای بیشتر یا کمتری صادر کرده است؟ آیا کیفرخواستها در حال کاهش هستند یا شتاب میگیرند؟
نسخه سادهشده این مشکل بسیار شبیه به یک مدل عفونت (معروف به رشد لجستیک یا انتشار باس) به نظر میرسد:
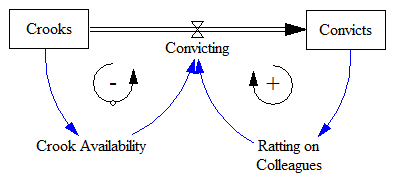
بنابراین، سؤال جالب این است که آیا میتوانیم – از نیمه راه تاریخ سیستم – تعداد نهایی کیفرخواستها و محکومیتهایی را که ایجاد میکند، تخمین بزنیم. این مملو از خطر است، به ویژه زمانی که اطلاعات مستقلی در مورد “فیزیک” سیستم، به ویژه جمعیت کلاهبرداران بالقوه برای دستگیری، ندارید.
به عنوان مقدمهای برای مدلسازی این موضوع، میخواستم ببینم تاریخها چگونه به نظر میرسند. مشکل اینجاست که دادههای موجود در github برای این کار مناسب نیستند. این دادهها بر اساس رویداد رابطهای هستند، نه سری زمانی بر اساس تحقیق. میدانم که احتمالاً میتوانم آن را با چند خط پایتون تبدیل کنم، اما تصمیم گرفتم کار را در Ventity انجام دهم، زیرا این امر زیرساختهایی را برای یک مدل پویای آینده ایجاد میکند.
ایده اصلی به شرح زیر است. به نظر میرسد هر ردیف از دادهها یک کیفرخواست است (بسیاری در هر تحقیق، گاهی اوقات بیش از یک مورد برای هر نفر). بنابراین، برای هر ردیف یک موجودیت ایجاد کنید (قبل از اینکه بفهمم هر کدام واقعاً چه چیزی را نشان میدهند، موجودیت را “item” نامیدم). سپس در طول زمان اجرا کنید و وضعیت (کیفرخواست یا محکومیت) را برای هر مورد محاسبه کنید. هر کدام فقط مانند یک تابع پلهای به نظر میرسند.
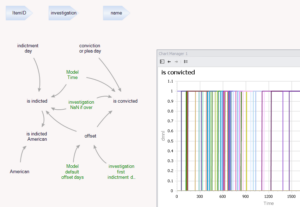
برای دیدن نتایج بر اساس تحقیق، تنها چیزی که لازم است مجموعهای از موارد بر اساس تحقیق است که تعداد کیفرخواستها و محکومیتها را جمع میکند. من همچنین یک موجودیت تحقیق ایجاد کردم تا چند مقدار را که مختص تحقیق هستند، مانند تاریخهای شروع و پایان، که برای نشان دادن اینکه آیا تحقیق در حال انجام است یا خیر، استفاده میشود، نگه دارد.
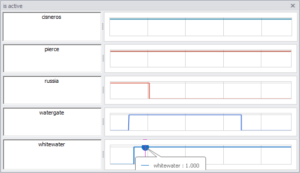
زمانبندی پیچیده است. چه زمانی ساعت را شروع میکنید؟ با شروع تحقیق رسمی، یا با اولین کیفرخواست، که میتواند یک سال زودتر یا دیرتر باشد؟ من تصمیم گرفتم تحقیقات را بر اساس تاریخ اولین کیفرخواست تراز کنم.
در واقع، مدل چیز زیادی ندارد؛ همه چیز در دادههای ورودی است که در اکسل قرار دارد. برای راحتی، از دادههای ورودی برای خاموش کردن برخی از تحقیقات “مزاحم” که هرگز نتیجه چندانی نداشتند، استفاده میکنم و فقط تحقیقات بزرگ با بیش از یک کیفرخواست را باقی میگذارم:
پس پاسخ چیست؟ در اینجا سریهای زمانی آمده است:
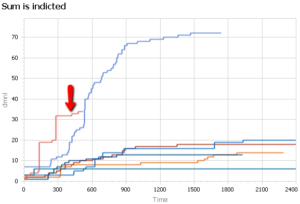
برای کل کیفرخواستها، بزرگ است – بزرگتر از واترگیت. با این حال، بسیاری از آنها اتباع روسیه هستند که ممکن است دستگیری آنها آسانتر باشد. (سایر تحقیقات عمدتاً آمریکاییها را هدف قرار میدهند).
اگر فقط کیفرخواستهای آمریکایی را بشمارید (بالا)، به نظر میرسد روسیه بیشتر در وسط جدول است، مثلاً تقریباً به اندازه ایران-کنترا.
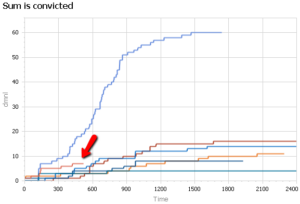
از نظر محکومیت، به نظر میرسد روسیه کمی جلوتر از جدول است، اما به اندازه واترگیت بزرگ نیست.
برخی مشاهدات دیگر:
- واقعاً تکاندهنده است که واترگیت چگونه بر همه دیگران سایه میافکند.
- همچنین تکاندهنده است که این چیزها چقدر طول میکشند. من سالهای طاقتفرسای صحبت در مورد لباس آبی را به یاد میآورم، اما این حتی یک رکورد هم نیست.
- به جز واترگیت، کیفرخواستها خیلی شبیه به یک فرآیند لجستیک به نظر نمیرسند. بیشتر شبیه یک فرآیند زوال است – کلاهبرداران با نرخ کسری ثابت دستگیر میشوند، نه بازخورد مثبت از “بیاحترامی در میان دزدان”.
- نتیجه نهایی؟ من شک دارم که بتوانیم با پیشبینی سری زمانی، چیز زیادی در مورد کیفرخواستهای آینده در تحقیقات روسیه بگوییم. با این حال، جالب است.
مدل و داده Ventity در فایل خریداری شده قرار دارد.

