من به یک مدل پویای جالب از همهگیری مواد افیونی برخورد کردم که هدف خوبی برای تکرار و نقد است:
پیشگیری از سوء مصرف مواد افیونی تجویزی و مرگ و میرهای پیشبینی شده ناشی از مصرف بیش از حد مواد افیونی در ایالات متحده
قوشی چن؛ مارک آر. لاروشل؛ دیویس تی. ویور؛ و همکاران.
اهمیت مرگ و میر ناشی از مصرف بیش از حد مواد افیونی در دهه گذشته سه برابر شده است. تلاشها برای مهار این روند بر محدود کردن عرضه مواد افیونی تجویزی متمرکز شده است؛ با این حال، اثرات کوتاهمدت چنین تلاشهایی ناشناخته است.
هدف پیشبینی اثرات مداخلات برای کاهش سوء مصرف مواد افیونی تجویزی بر مرگ و میرهای ناشی از مصرف بیش از حد مواد افیونی از سال 2016 تا 2025.
طراحی، تنظیمات و شرکتکنندگان این مدل پویایی سیستم (ریاضی) همهگیری مواد افیونی ایالات متحده، نتایج افراد شبیهسازی شدهای را که در مصرف غیرپزشکی مواد افیونی تجویزی یا غیرقانونی شرکت میکنند، از سال 2016 تا 2025 پیشبینی کرد. این تجزیه و تحلیل در سال 2018 با کالیبره کردن گذشتهنگر مدل از دادههای سال 2002 تا 2015 از نظرسنجی ملی مصرف مواد مخدر و سلامت و مراکز کنترل و پیشگیری از بیماری انجام شد.
…
نتیجهگیری و ارتباط یافتههای این مطالعه نشان میدهد که مداخلات هدفمند برای سوء مصرف مواد افیونی تجویزی مانند برنامههای نظارت بر تجویز، در بهترین حالت، ممکن است تأثیر متوسطی بر تعداد مرگ و میرهای ناشی از مصرف بیش از حد مواد افیونی در آینده نزدیک داشته باشد. مداخلات سیاستی اضافی به فوریت برای تغییر مسیر همهگیری مورد نیاز است.
این مدل به طور کامل در محتوای تکمیلی توضیح داده شده است، اما متأسفانه در R پیادهسازی شده و با حروف یونانی توضیح داده شده است، بنابراین نمیتوان آن را مستقیماً اجرا کرد:
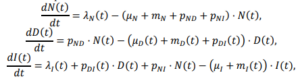
این در واقع برای من خوب است، زیرا فکر میکنم اگر معادلات را خودم پیادهسازی کنم، بیشتر از زمانی که کسی یک مدل در حال کار به من بدهد، یاد میگیرم.
در حالی که R به شما امکان دسترسی به ابزارهای فوقالعادهای را میدهد، فکر میکنم محیط مناسبی برای طراحی و آزمایش مدلهای پویای با اندازه قابل توجه نیست. شما نمیتوانید به راحتی همه چیزهایی را که در حال رخ دادن است بررسی کنید، و تسهیلات آسانی برای آزمایش تعاملی وجود ندارد. بنابراین، من کنجکاو بودم که آیا این موضوع در این مورد مشکلساز خواهد شد یا خیر، زیرا مدل کوچک است.
در اینجا چیزی است که در Vensim تکرار شده است:
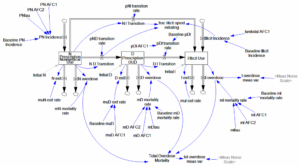
پیچیده به نظر میرسد، اما پیچیده نیست. اساساً آبشاری از فرآیندهای تأخیر مرتبه اول است: خروجی از هر انبار به سادگی یک بخش در واحد زمان است. هیچ حلقه بازخورد در مقیاس بزرگ وجود ندارد.
نقاط اتصال
بخش “پیچیده” از پارامترهای با تخمینهای “نقطه اتصال” ناشی میشود. اینها به سادگی توابع پیوسته با مشتقات ناپیوسته هستند، جایی که ناپیوستگی در یک نقطه مشخص رخ میدهد. مثلا:
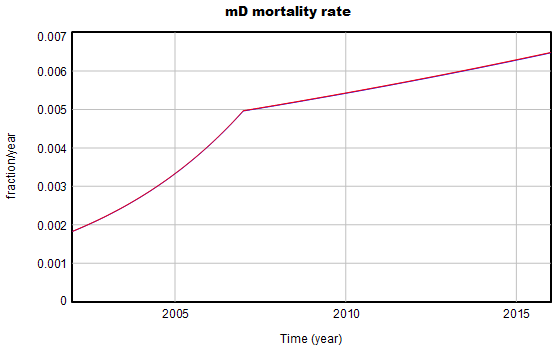
پارامترهای برخی از این منحنیها یکی یکی از دادههای گزارش شده در مقاله تخمین زده میشوند. تخمینهای حلقه باز گاهی اوقات در مدلهای یکپارچه کار میکنند (برخلاف این)، به ویژه اگر بازخورد کمی وجود داشته باشد و خطای اندازهگیری مشکل بزرگی نباشد، همانطور که در این مورد وجود دارد.
معادله نقطه اتصال به این شکل است، جایی که β پارامتر مورد نظر است:
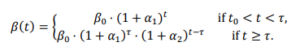
من عبارت (1+rate)^time را آزاردهنده میدانم، زیرا از نظر ابعادی ناسازگار است، مگر اینکه زمان بدون بعد باشد. بنابراین، با نادیده گرفتن توصیه اخیر خودم، در ابتدا این عبارات را به EXP(rate*time) ترجمه کردم. معلوم شد که خوب کار نمیکند، زیرا برخی از نرخها بزرگ هستند – 20 یا 30 درصد در سال. بنابراین، در نهایت به نسخه مقاله بازگشتم، با یک ضریب برای تطبیق واحدها:
mD mortality rate = Baseline mD mortality rate *( 1+mD AFC1*one year)^((MIN(Time,mDtau)-INITIAL TIME)/one year) *( 1+mD AFC2*one year)^((MAX(Time,mDtau)-mDtau)/one year)
با کار کردن نقاط اتصال، پارامترها را از جداول موجود در مقاله وارد کردم و مدل را اجرا کردم.
رفتار و کالیبراسیون
رفتار مدل به طور کلی بسیار نزدیک به نتایج و دادههای منتشر شده است. مثلا:
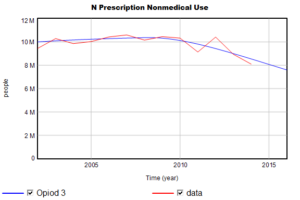
من یک واریانس قابل توجه پیدا میکنم، که فکر میکنم منشأ جالبی دارد:

کل مرگ و میر تا حدودی به سمت بالا متمایل است. ردیابی علی و کشف اینکه ترکیبی از مصرف بیش از حد D و مصرف بیش از حد N باید علت باشد، نسبتاً آسان است (مصرف بیش از حد I و برخی از نامزدهای دیگر رد میشوند زیرا توسط دادهها محدود شدهاند). تغییر جزئی نرخ مرگ و میر پایه Md، انحراف در منحنیهای بالا را از بین میبرد.
فکر میکنم این مشکل به این دلیل ایجاد میشود که پارامترهای گزارش شده میانگین جمعیت از مجموعهای از شبیهسازیهای مونت کارلو هستند:
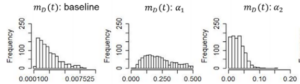
از مقاله میدانیم توزیعهای حاشیهای پارامترها را میدانیم، اما توزیعهای مشترک را نمیدانیم. برخی از توزیعها نیز بسیار متمایل هستند. بنابراین، رفتار مدل با همه پارامترهای میانگین حاشیهای لزوماً با رفتار میانگین مدل مطابقت ندارد.
من پارامترها را با و بدون فیلتر کالمن مجدداً تخمین زدم و متوجه شدم که انحراف همانطور که انتظار میرود ناپدید میشود. شبیهسازی زنجیره مارکوف مونت کارلو نشان میدهد که در واقع همبستگیهای قوی بین برخی پارامترها وجود دارد. در اینجا یک ماتریس پراکندگی از زیرمجموعهای از فضای پارامتر بزرگ وجود دارد:

دامنه
آنچه واقعاً تکاندهنده میدانم تفاوت در رویکرد بین این مدل و مدلهای SD قبلی همهگیری مواد مخدر است. در این مدل، هیچ رفتار صریحی وجود ندارد و هیچ نمایشی از منابع (مانند دسترسی به مواد مخدر، فروشندگان، قیمتها، تلاشهای اجرایی) که ممکن است باعث شود نرخها به همان شکلی باشند که هستند، وجود ندارد. این را با موارد زیر از لوین، هیرش و رابرتز، مواد مخدر و جامعه: شبیهسازی سیستمها مقایسه کنید:
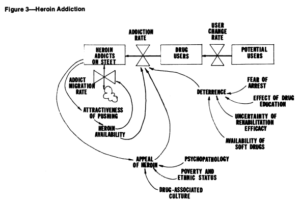
در اینجا (و در سایر کارهای SD)، برخی از محرکهای کلیدی مانند بازدارندگی و حلقه مثبت کاربرانی که فروشنده میشوند و کاربران جدید را جذب میکنند، نشان داده شدهاند.
کدام رویکرد بهتر است؟ فکر میکنم بستگی به هدف شما دارد. مدل فعلی ساده و به خوبی در “فیزیک” انبارهای جمعیت و جریانها پایه گذاری شده است. این امر شناسایی پارامترهای خاص (به ویژه شیبهای بخشهای مختلف نقطه اتصال) را که تاثیر بالایی بر مرگ و میر آینده دارند، آسان میکند.
در عین حال، استفاده سنگین از نقاط اتصال (یا به طور کلی، پارامترهای متغیر با زمان) اساساً تمام رفتار جالب مدل را برونزا میکند. اگر میخواهید نقاط اهرمی را پیدا کنید، به مدلی نیاز دارید که به اندازه کافی از سیستم را در بر گیرد تا حلقههای بازخورد کلیدی را شامل شود. این مدل نشان میدهد کجا را جستجو کنید، زیرا جمعیتهای بزرگ یا روندهای قوی نشان میدهند که تعداد قابل توجهی از افراد آسیب خواهند دید.
اگر میخواهید بدانید چگونه و چرا اوضاع در حال تغییر است، یا اگر میخواهید با ذینفعان برای رفع سیستم تعامل داشته باشید، باید اطلاعات بیشتری در مورد محرکهای علی داشته باشید. آیا هجوم کاربران غیرقانونی به دلیل تقویت دهان به دهان است؟ یا آیا فروشندگان مواد مخدر درآمد خود را در بازاریابی مجدداً سرمایهگذاری میکنند؟
مدل
این آرشیو شامل مدل در قالبهای Vensim .mdl و .vpm، با فایلهای کنترل بهینهسازی پشتیبانی و مجموعه دادههای نشان داده شده در بالا است. باید در PLE کار کند، اما شما واقعاً به Pro یا DSS نیاز دارید تا تخمین پارامتر و سایر ویژگیهای پیشرفته را بررسی کنید.
